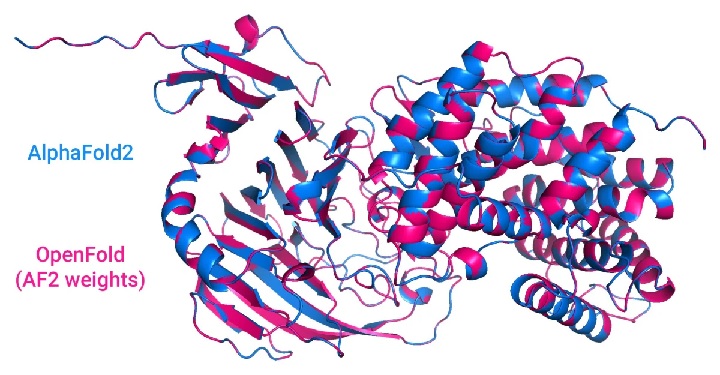
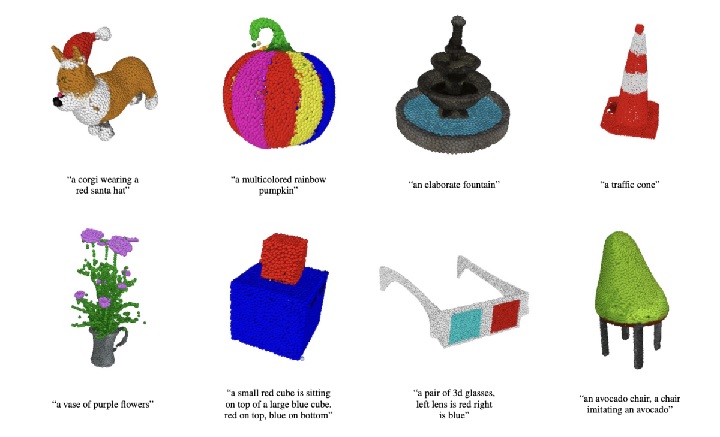
展望2023年对人工智能AI的期待
正如一位在商业上相当成功的作家曾经写道,“夜晚是黑暗的,充满了恐惧,白天是光明的,美丽的,充满了希望。” 这是适合人工智能的图像,就像所有技术一样,它有其优点和缺点。例如,像Stable Diffusion这样的艺术生成模型已经带来了令人难以置信的创造力,为应用程序甚至全新的商业模式提供动力。另一方面,它的开源性质让不良行为者可以利用它来大规模制作深度造假——与此同时,艺术家们抗议说它正在从他们的作品中获利。
2023 年人工智能 AI 的发展方向是什么?监管会控制 AI 带来的最坏情况,还是会打开闸门?强大的、变革性的新形式的 AI会像 ChatGPT 一样出现,颠覆曾经被认为不受自动化影响的行业吗?

图片来源:约翰·隆德 (在新窗口中打开)/盖蒂图片社
期待更多(有问题的)艺术生成 AI 应用程序
随着Lensa的成功,Prisma Labs 的 AI 驱动的自拍应用程序迅速走红,你可以期待很多类似的应用程序沿着这些方向发展。并期望他们也能够被骗去创造 NSFW 图像,并过度地性感化和改变女性的外表。
Mozilla 基金会的高级政策研究员 Maximilian Gahntz 表示,他预计将生成式 AI 整合到消费技术中将放大此类系统的影响,无论是好的还是坏的。例如,Stable Diffusion 从互联网上输入了数十亿张图片,直到它“学会”将某些单词和概念与某些图像相关联。文本生成模型通常很容易被骗去支持攻击性观点或产生误导性内容。
Knives and Paintbrushes 开放研究小组的成员 Mike Cook 同意 Gahntz 的观点,即生成式 AI 将继续证明是一种主要且有问题的变革力量。但他认为 2023 年必须是生成式人工智能“最终把钱花在嘴上”的一年。

由 TechCrunch 提示,Stability AI 建模,在免费工具 Dream Studio 中生成。
“仅仅激励专家社区 [创造新技术] 是不够的——要使技术成为我们生活的长期组成部分,它必须要么让某人赚很多钱,要么对日常生活产生有意义的影响普通大众,”库克说。“所以我预测我们会看到大力推动生成式 AI 实际上实现这两件事之一,并取得不同程度的成功。”
DeviantArt发布了一个基于 Stable Diffusion 的 AI 艺术生成器,并根据 DeviantArt 社区的艺术作品进行了微调。艺术生成器遭到了 DeviantArt 长期用户的强烈反对,他们批评该平台在使用他们上传的艺术来训练系统时缺乏透明度。
最受欢迎的系统——OpenAI 和 Stability AI——的创建者表示,他们已采取措施限制其系统产生的有害内容的数量。但从社交媒体上的许多代人来看,很明显还有很多工作要做。
Gahntz 说:“数据集需要积极管理以解决这些问题,并且应该受到严格审查,包括来自那些倾向于吃亏的社区的审查。”他将这一过程与社交媒体中关于内容节制的持续争议进行了比较。
主要资助 Stable Diffusion 开发的 Stability AI 最近屈服于公众压力,表明它将允许艺术家选择退出用于训练下一代 Stable Diffusion 模型的数据集。通过网站 HaveIBeenTrained.com,权利持有人将能够在几周后的培训开始前请求退出。
OpenAI 不提供这种选择退出机制,而是更愿意与 Shutterstock 等组织合作,以许可其图片库的一部分。但考虑到它与 Stability AI 一起面临的法律和纯粹的宣传阻力,它效仿可能只是时间问题。
法院最终可能会强制执行。在美国,微软、GitHub 和 OpenAI 在集体诉讼中被起诉,指控他们让 Copilot(GitHub 的智能建议代码行的服务)在不提供信用的情况下重复许可代码的部分,从而违反了版权法。
也许是预料到了法律挑战,GitHub 最近添加了一些设置,以防止公共代码出现在 Copilot 的建议中,并计划引入一项功能,该功能将引用代码建议的来源。但它们是不完善的措施。至少在一个例子中,过滤器设置导致 Copilot 发出大量受版权保护的代码,包括所有归属和许可文本。
2022 年,少数人工智能公司占据了舞台,主要是 OpenAI 和 Stability AI。但钟摆可能会在 2023 年重新转向开源,因为构建新系统的能力超出了 Gahntz 所说的“资源丰富且功能强大的 AI 实验室”。
他说,社区方法可能会导致在构建和部署系统时对系统进行更多审查:“如果模型是开放的,如果数据集是开放的,那将能够进行更多的关键研究,这些研究已经指出了很多与生成人工智能相关的缺陷和危害,而这通常很难实施。”